
编者按:数据、深度学习框架及算力作为人工智能的基础设施,促进着人工智能的高速发展,为各行业在人工智能产业落地上发挥着至关重要的作用。雷海也在持续不断的在海事+AI上开展投入,并已取得部分成果,公众号未来将推出专题文章,对AI中的相关基础概念进行探讨。
人工智能(Al)技术已经成为国家发展战略,也是未来几年世界主要强国投入的主要技术万向,推动AI技术发展和应用的三大助力是:大数据、算法和算力,本期文章专门探讨Al算力方面的相关概念。
算力的释义:通过处理数据,实现特定结果输出的计算能力。实现算力的载体是各种计算单元,如CPU、GPU、NPU、FPGA 等,并由计算机、服务器、集群、边缘侧终端等承载,各种数字化应用都少不了算力的加工和计算,算力越大代表综合计算能力越强。
根据业界共识,算力可分为基础算力、智能算力和超算算力三类,分别提供基础通用计算、人工智能计算和科学工程计算。基础算力,是以CPU芯片为核心的计算机、服务器所提供的算力,典型为戴尔、联想等厂商提供的计算机、服务器。智能算力通常以GPU、FPGA、NPU等芯片为核心的加速计算平台提供Al训练和推理的算力,典型有英伟达、华为提供的GPU、NPU 板卡。超算算力基于超算计算机,通常集群形式提供大规模算力,典型有美国橡树林国家实验室,中国天河二号超算中心等。
接下来,我们重点探讨人工智能计算方面的概念和内容。
一、A1的典型应用场景
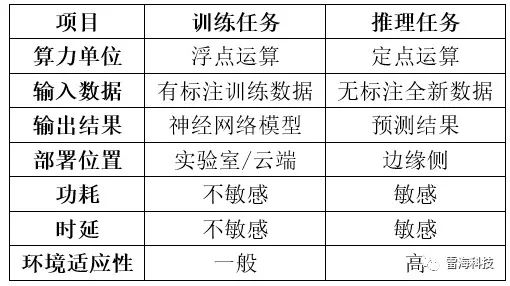
Al应用通常分为训练任务和推理任务,是人工智能领域中两个重要的应用场景,它们二者之间在算法,数据加工、模型输出、算力要求等方面有显著的区别。以深度学习(神经网络)为例,来说明训练和推理的区别,其工作界面如图1所示。
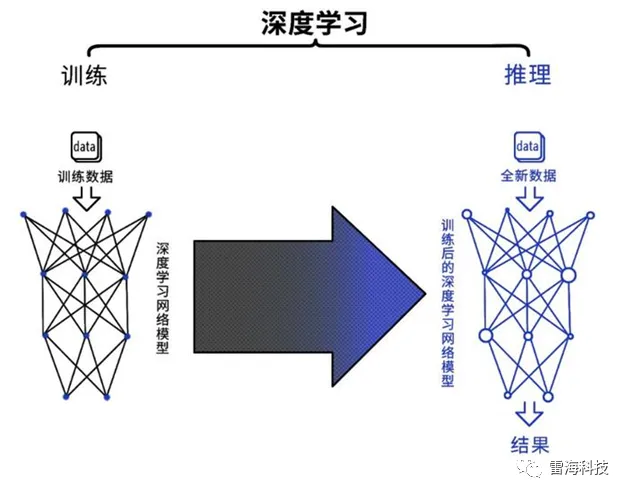
训练任务是指使用大量的标记过的数据和计算资源来训练复杂深度学习模型,以实现高精度的预测和分类。这个过程需要进行大量的矩阵运算和参数优化,在训练过程中需要消耗可观的计算资源和存储空间,训练任务的输出是深度学习网络模型。训练任务所需要精度更高,算力也更高,并且需要有一定的通用性,以便完成各种学习任务,因此目前训练的算力一般都采用16位浮点数(小数)进行衡量,也有32位浮点数计算,甚至64位双精度数据的计算,训练任务一般部署在实验室或者云端。
相比之下,推理任务则是在已经训练好的深度学习网络模型上进行,目的是通过输入全新数据来预测结果。在这个过程中,需要对输入的数据进行计算,以得到预测结果,这个过程相对简单,需要的计算资源也较少,对精度和算力要求较低,因此一般推理任务都是采用8位整型(INT8)对算力进行标志,计算时也都是进行整型运算,一般部署在边缘和终端侧,通常要求功耗低、成本低,且能适应更复杂的环境条件,属于“最后一公里”的AI应用。
二、算力的单位
市面上出现了的很多芯片,都使用了诸如“每秒可达XX亿次运算”算力的概念,但提到算力的能力,一定不能脱离以下几个方面:
在各种计算单元中,常见的数据类型有:
算力计算单位术语有:
下面是衡量浮点运算性能的度量单位:
对于整形运算,通常使用TOPS(tera Operations Per Second),即每秒一万亿的整数运算作为计算单位。
需要注意的是,衡量浮点和整形算力时,还需要考虑数据类型。例如,同样的双精度浮点FP64和单精度浮点FP32,10TFLOPS的算力,双精度型显然算力更高。
同样地,整型INT8类型的10TOPS算力,要大于整型INT4的10TOPS算力。
三、AI任务与算力
训练任务需要构建模型,更多地进行浮点运算,推理任务根据已生成的模型进行结果预测,更多地执行整型运算。因此,衡量算力时,训练任务一般使用FLOPS单位,而推理任务一般采用整型INT8进行度量。
以下是几种典型AI芯片/模块的算力描述:
以上板卡用于构建神经网络模型,并注重绝对的计算能力。
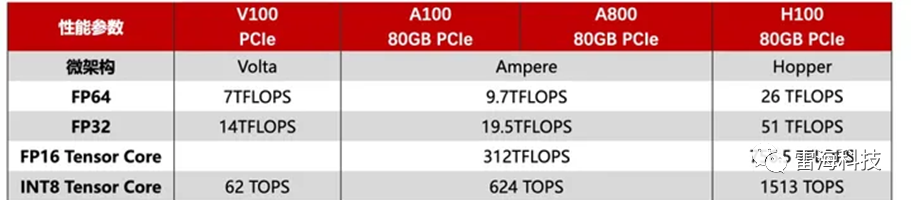
再看国内厂商瑞芯微电子的一款RK3588处理器性能参数列表。

这款处理器标注了6TOPS的AI算力,再继续查询手册发现,这个6TOPS算力基于INT8,但比较算力这一项,比英伟达上述板卡要弱不少,但是RK3588定位是消费电子、边缘侧终端设备,具有低功耗、性价比高、时延小的地点,对于开展推理任务优势明显。
上一篇:公司雷达模拟器产品获得软件产品证书 下一篇:聚焦2023上海国际海事展